Urgent: Google's data grab grabs mathematics
"For advice specific to your situation you will need to talk to a lawyer."


Will Google carve math at the joints?
Mathematicians who tune in to the recording of Tony Wu’s February lecture at the Institute for Pure and Applied Mathematics at UCLA may be alarmed, or dismayed, or nonplussed, or merely puzzled, to discover that Wu’s employers at Google perceive the entirety of contemporary mathematics, including “all the arXiv papers… [and] all the internet tokens written similarly to arXiv papers,” as a mass of mathy data. These data, as Wu reported, are tossed into a virtual cauldron, where they slosh around1 while precooking algorithmically with Google’s Pathways Language Model as training data, until they get reconstituted and packaged as Minerva, pictured above.
Many years ago I had the privilege of being invited to a dinner where the philosopher W. V. O. Quine was the guest of honor. I naturally asked — as would anyone who had read Quine’s Word and Object — whether undetached rabbit parts would be on the menu.
Track "undetached rabbit parts" by arche3.0, license CC BY-NC-SA
In his observations on the indeterminacy of translation, Quine famously argued2 that a linguist who observes an informant utter “gavagai” while indicating (what to the linguist appears to be) a scampering rabbit may make the mistake of translating “gavagai” by rabbit when in reality the informant’s finger points to undetached rabbit parts. This scenario may seem implausible to those who believe that language “carves nature at the joints”3 and that “rabbit” is a natural kind in a way that “undetached rabbit part” is not. Quine’s point was that philosophy could not coherently claim that language automatically tracks a division into natural kinds:
…on the whole we may meaningfully speak of interlinguistic synonymy only within the terms of some particular system of analytical hypotheses.4
In the end roast beef was served at dinner,5 and Quine’s authentic curiosity about languages was on display in his exchange with a group of visiting Chinese scholars.
On the detachment of mathematicians
Had the mathematicians present at the IPAM conference been familiar with Quine’s thesis on the indeterminacy of translation, they would have hesitated to follow Patrick Massot down the rabbit hole of his system to translate Lean code into informal proofs, whether or not they agree with Quine’s analysis. Similarly, although Minerva, on Wu’s account, makes more sense than Christian Szegedy’s proposal to autoformalize by treating input text as pictures, Quine’s thesis should make mathematicians skeptical of any claim that “the content is the same,” as Massot put it, at the two ends of any automatic process of formalization of mathematical text.
Philosophers who study the objectivity of mathematics are rightly concerned with the question of whether the objects we study, like groups or manifolds or sets, are in fact natural kinds. This may not matter to the mathematicians who write about them, but at the level of mathematical practice we can ask whether a published article, or an arXiv preprint, is a natural kind. Anyone who has been asked by a referee to revise an article knows that matters can’t be that simple; but then where are the joints at which our articles should naturally be carved? Do they separate theorems, or lemmas, as the conventional organization of our articles suggests? Does an article naturally separate into something on the order of ideas, into which it comes apart of its own accord under the eyes of a reader as attentive as Zhuangzi’s butcher Ding?6 Or should the article aspire to be apprehended as a work, as in “Collected Works of,” a compact unity, like a song or a sonnet, that resists being chopped up for a third party’s algorithmic goulash?
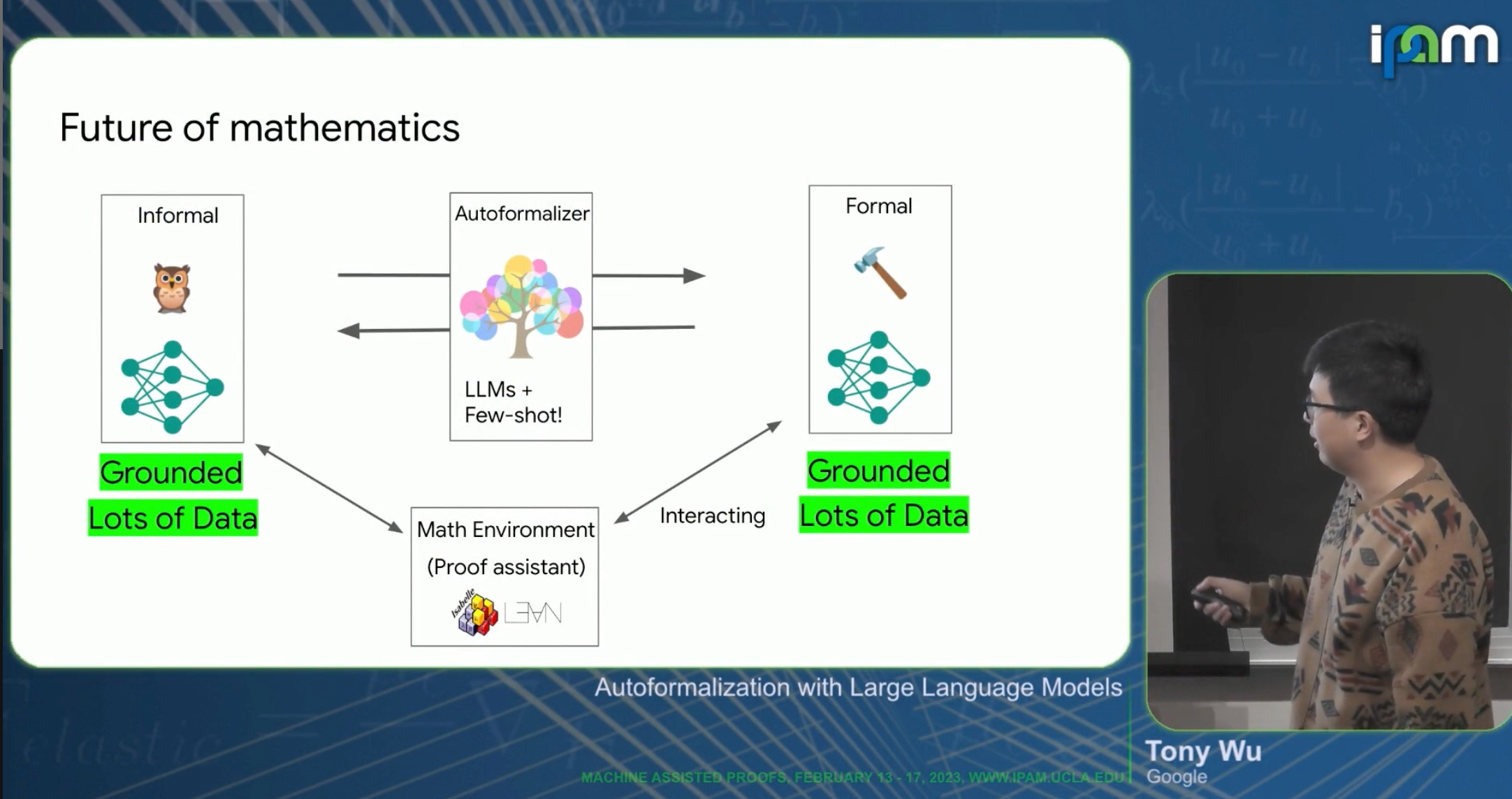
It would be truly impressive if Wu’s mathy data carved the arXiv at its joints, exposing its underlying ideas. I find this extremely unlikely; Wu himself admitted7 that Minerva had difficulty formalizing definitions. All of these questions about how much of mathematics the formal systems are really preserving should have been asked at the IPAM workshop; perhaps they were in Q&A sessions that were not recorded.
The urgency in the title, however, is connected to a more urgently disconcerting form of detachment, on the part of the mathematicians in Wu’s audience, than that from familiar obsessions of 20th century philosophy. Take another look at Wu’s mathy data graphic, and at his acknowledgment that it includes “all the arXiv papers.” Set aside the question of whether it is morally acceptable for Google or any of the Silicon Valley behemoths to appropriate the entirety of contemporary mathematics for its own purposes. It may in fact be strictly illegal copyright infringement.
Readers who post articles on arXiv are familiar with that moment of irritation when you realize that you cannot finish your submission and get on with urgent business until you have chosen one of the available licenses. One of the options is

which stipulates that
You may not use the material for commercial purposes
and that
If you remix, transform, or build upon the material, you may not distribute the modified material.
Google is not a charitable organization; all of Google’s purposes are "commercial” unless demonstrated not to be; and Google’s training process, on Wu’s telling, looks an awful lot like remixing, transformation, and building upon. Nevertheless, the mathy data Minerva has been gobbling up undoubtedly contains a considerable amount of material that is protected by BY-NC-ND 4.0 from precisely such gobbling.
Wu formulated the rationale for this process with admirable candor (at 4’45”):
If you have the money to train the model, then go ahead [chuckle].
Readers may have encountered a similar approach to pragmatic ethics if they have attended Mafia seminars on kneecapping and fingernail extraction. It is astonishing to me that the audience at Wu’s lecture was so detached from the circumstances of tech industry attempts to appropriate all human creation for its own commercial purposes — circumstances that were very much in the news at the time of the IPAM workshop, as I recall below — that no one raised the issue of copyright infringement at Wu’s talk.
This will all be fought out in the courts
Up to now I have always chosen arXiv.org’s perpetual, non-exclusive license. When I asked arXiv’s User Support team whether this license also prohibits commercial use, this was the reply:
The arXiv perpetual license only provides arXiv with the minimal non-exclusive right to distribute the submission. We cannot provide legal advice regarding any specific situation, use, or other circumstances. For advice specific to your situation you will need to talk to a lawyer.
With its limited resources arXiv provides a valuable service to the community, and it’s understandable that it doesn’t have the capacity to mount legal challenges to abusive exploitation of its data. It’s particularly unlikely that arXiv would challenge Google, given that Google, Inc. is the unique Gold Sponsor listed on arXiv’s Supporters page.
But legal challenges to generative AI are very much the order of the day, as anyone keeping up with the news would have known in February. It was one of the main topics discussed at an event, already mentioned here, that I attended at Triple Canopy the week before the IPAM workshop. A few weeks earlier, artnet.com had reported that
Artists and Illustrators Are Suing Three A.I. Art Generators for Scraping and ‘Collaging’ Their Work Without Consent
Another class action suit was reported in artnet.com just one day after Wu’s talk. More recently, the Italian data-protection authority banned ChatGPT on the grounds that
there was no legal basis to justify "the mass collection and storage of personal data for the purpose of 'training' the algorithms underlying the operation of the platform."
While European laws strongly protect private data, the outcome of the class action suits in the US will probably hinge on the interpretation8 of the notion of “fair use,” the doctrine Google used in its successful defense of Google books. Katherine Forrest, former federal judge for the Southern District of New York, argues that the precedent doesn’t apply:
…the ultimate difference between [generative AI] and say, Google Books, is that the point of Google Books was to allow you to search for the book, and it gave you a portion of the copy for you to access. The point was discovering the underlying work. For generative AI, the value is not necessarily the discovery of the underlying creative work but rather a replacement of the work with something else. It is 100 percent copy leading to 100 percent replacement. And it’s absolutely commercial. This will all be fought out in the courts.9
The closest the mathematical community has come, in my experience, to anything remotely like a class action suit was the Elsevier boycott that Tim Gowers launched in 2012. The Cost of Knowledge statement that was endorsed by more than 20000 people explained the boycott by reference to “scandals, … bundling practices, exorbitant prices, and lobbying activities” that together
suggest a publisher motivated purely by profit, with no genuine interest in or commitment to mathematical knowledge and the community of academic mathematicians that generates it. Of course, many Elsevier employees are reasonable people doing their best to contribute to scholarly publishing, and we bear them no ill will. However, the organization as a whole does not seem to have the interests of the mathematical community at heart.
A specific charged leveled at Elsevier was that their business model was based on repackaging the work provided, free of charge, by authors and peer reviewers, and then selling it back to their institutions’ libraries at outrageously inflated prices, having added next to nothing in the process. Minerva, like the other generative AI systems, reproduces the first part of this business model without even asking the creators’ permission, then claims the package as its own product. I signed the Cost of Knowledge statement and I continue to boycott Elsevier. But Elsevier’s abuses pale in comparison with the harm caused by the practices that have made the tech industry the target of class action suits and with the privacy concerns that have brought the attention of European regulatory agencies. So I hope that the Cost of Knowledge signatories who attended Wu’s talk will be attentive to these problems in the future, as the tech industry continues its attempt to repackage the mathematical community as a stream of private training data.10
Mustering “community support”

Last November, in the aftermath of the Fields Medal Symposium that I helped to organize, I was briefly in an e-mail exchange including Tony Wu. At one point he sent the following message as part of his continuing campaign to muster community support:
On Nov 18, 2022, at 16:45, Tony Wu <tonywu0206@gmail.com> wrote:
Michael Harris suggested more meetings, building on this one, on the subject of
AI and math.Thanks, I agree with the proposal very much! I think the field is growing rapidly and both fields (math and AI) would benefit immensely from collaborations / interactions.
Let me add a few more pointers in case people in this thread are interested in relevant workshops:
MATH-NLP: https://sites.google.com/corp/view/1st-mathnlp/home
FLAIM: https://www.ihp.fr/en/events/conference-flaim-formal-languages-ai-and-mathematics. A great workshop recently held by Meta and IHP, where many formal mathematicians and AI researchers attended.
An upcoming workshop on machine assisted proofs at IPAM: https://www.ipam.ucla.edu/programs/workshops/machine-assisted-proofs/?tab=speaker-list
And I believe we will continue organizing MATHAI workshop series in the coming years. Hope to see many of you in the future!
Cheers,
Tony
To clear up an obvious misunderstanding, I responded immediately with my own reasons for withholding community support:
Dear Tony,
Thank you for providing this list. I want to clarify what I proposed. Speaking only for myself, but I think also for the majority of working mathematicians, I am put off by exaggerated claims (copied from the second Math-AI meeting home page) like
The machine learning community has contributed significantly to mathematical reasoning research in the last decades,
and a meeting whose goals include
to find out “when machines can surpass human experts in different mathematical domains?”
seems to me completely misguided.
My next Substack newsletter11 will explain, among other things, why I'm disinclined to take part in any meetings with significant participation by or support from the tech industry. I don't wish to offend anyone, but I strongly believe that the ultimate goals of scholars and of industrial corporations are very different, even if they can occasionally overlap. I have next to no sympathy for the corporations, who dominate media coverage of these developments, for a variety of reasons; of course they also have the means to dominate the organization of conferences and workshops (a partial list of sponsors of this workshop is copied below. This year's sponsors are listed here).
Computing in any form is irrelevant to my own work as a mathematician. My primary reason for being involved with these matters at all is to try to restore some balance to the discussion. The Toronto meeting showed, happily, that this is possible in a meeting of scholars. Outside academia it seems extremely challenging.
The organizers of the Fields event discussed the possibility of inviting prominent researchers from prominent industrial labs working on automation of mathematics. In the end we agreed, as I wrote to the other organizers, that
[here I inserted the comment on “Researchers X, Y, and Z” that was reproduced here, adding parenthetically that The other organizers are not responsible for the word "predatory."]
I'm ready to believe that some aspects of mathematics can eventually benefit from interaction with AI, but not in a framework driven by the needs of the tech industry, and certainly not when the goals are like the one quoted above.
Michael
The liquid imagery is appropriate. “ChatGPT needs to ‘drink’ a 500 ml bottle of water for a simple conversation of roughly 20-50 questions and answers, depending on when and where ChatGPT is deployed.” See J. Tyrell, “AI water footprint suggests that large language models are thirsty,” April 11, 2023.
W. V. O. Quine, Word and Object, MIT Press (1960), Chapter 2, especially §12. The expression has given rise to a meme as well as to the track reproduced above.
The metaphor is attributed to Plato’s Phaedrus, 265e, though it also appears, at roughly the same time, in Zhuangzi’s allegory of the butcher Ding and the Lord Wenhui.
Quine, op. cit., §16.
The hosts were evasive when I asked whether Quine had been offered undetached rabbit parts as an option.
As the butcher Ding put it, "There are spaces between the joints, and the blade of the knife has really no thickness. If you insert what has no thickness into such spaces, then there’s plenty of room — more than enough for the blade to play about it.” Zhuangzi, Basic Writings, translated by Burton Watson.
See Wu’s talk, around 51’.
With luck this will give me an excuse in the near future to write about Andy Warhol and Prince.
The legal issues may take some time to settle, but for my purposes it doesn’t matter what the courts will decide. To quote a New Yorker article entitled “Is A.I. Art Stealing from Artists?” with regard to the class action suit, Whatever their legal strengths, such claims possess a certain moral weight.
From a Guardian interview with Timnit Gebru, whom Google fired for honesty:
On questions about AI systems using copyrighted material, a spokesperson says that Google will “innovate in this space responsibly, ethically, and legally”, and plans to “continue our collaboration and discussions with publishers and the ecosystem to find ways for this new technology to help enhance their work and benefit the entire web ecosystem”.
Reassuring for us slugs in the ecosystem, isn’t it?
1. Google, for a long time yet, IS ABOVE the law. Nobody may flatout copy entire books against all copyright provisions. Googlebooks does just that, nobody cares (?), nobody acts (!). That is the main problem here.
Same now with arXiv etc. - which is public though anyway, so up for graps (legally!) by anybody incl. Google.There IS though a license attached to arXiv material and it requires citing and/or non-modifying etc. Will they bother?
2. Garbage in - garbage out. AI up to now (in particular chatGPT) mixes input snippets to output ouevres. Nice enough, but always within the bounds of the received input material. Nothing genuinely new. Difficult to tell though, where it comes from, whether / that it is just copy&paste. Same might happen to math articles, where already today some 99% of us do not enter into the details of stuff too distant of our own tiny circle of competence. In the future, we will see Sokal-style "Fashionable Nonsense" also in math.
It's always an exciting sign when a writer references Quine's "gavagai" story with its "undetached rabbit parts." The issue of whether the world can be "cut at its joints" was also central to medieval philosophical debates about the nature of language and representation. Good to see we are still debating this 800 years later. I hope you'll write more about this question vis-a-vis the 'naturalness' of the object of mathematics.