

(My) shallow thoughts about deep learning, II
The June workshop on "AI to Assist Mathematical Reasoning," three sessions with industry participation

…Silicon Valley and venture capitalists are not actually interested in developing technology for the betterment of society . . . What they’re interested in is making money off of whatever hype cycle they are going to gin up next.
That’s Paris Marx, host of the Tech Won’t Save Us podcast, quoted on June 22, 2023, in the Financial Times — not a Marxist publication. It’s only one opinion, of course, but it is not a marginal one, even among mathematicians. Even if any of the academics attending The Workshop shared this jaundiced view of the industry — which I seriously doubt — The Workshop’s format would appear to make it impossible to express this opinion even in the mildest fashion.1
What most surprised me in continuing my review of The Workshop talks was that some computer scientists, including those working for industry, scored much higher than the mathematicians on practically all the criteria in my scorecard. A few of them even alluded to Paris Marx’s observation, though less starkly. On second thought, this should not have been at all surprising. Professional structures and norms force even purely theoretical computer scientists to pay close attention to what more than one panelist called the “real world,” which, to paraphrase James Joyce, is the nightmare from which many pure mathematicians give the impression of having awakened long ago.
Day 2, Concentration of Machine Learning Capabilities and Open Source Options

This panel, moderated by Terry Tao, featuring only the single panelist Stella Biderman (henceforth SB), was my biggest discovery of The Workshop. SB is the representative of military contractor Booz Allen Hamilton I warned about a few weeks ago, and for that reason I was expecting someone on the model of Bond villain and occasional arms dealer Ernst Stavro Blofeld

{kind=link}
Instead, Biderman, a “mathematician and artificial intelligence researcher at Booz Allen Hamilton and EleutherAI who specializes in natural language processing, ML interpretability, and AI ethics,” made the most cogent remarks of the entire Workshop on issues that count on my scorecard, and the grades below reflect that.
SB’s presentation here and in a later panel discussion displayed a commitment to the open source model that could be taken to be emblematic of the “democracy of the multitude” in the vision of post-Marxists Michael Hardt and Toni Negri:
We might also understand the decision-making capacity of the multitude in analogy with the collaborative development of computer software and the innovations of the open-source movement. … When the source code is open so that anyone can see it, more of its bugs are fixed, and better programs are produced… [Eric] Raymond calls this, in contrast to the cathedral style, the bazaar method of software development, since a variety of different programmers with different approaches and agendas all contribute collaboratively. … The important point here is that open-source, collaborative programming does not lead to confusion and wasted energy. It actually works. One approach to understanding the democracy of the multitude, then, is as an open-source society, that is, a society whose source code is revealed so that we all can work collaboratively to solve its bugs and create new, better social programs.2
Why would such a person be in the military-industrial complex at all, especially at a corporation known for supplying surveillance technology to repressive regimes? Is Biderman practicing The Politics of Subversion, to borrow the title of an earlier book by Negri? A simpler explanation may be hidden in SB’s own observation that
I come from what is probably the best funded research organization in this space. We have tons of GPUs, we train models with 10s of billions of parameters all the time.
SB’s talk immediately illustrated what the word “Centralization” in the title means:

When we talk about centralization of capabilities, SB explained, we are also talking about access. And access is expensive.

The figures on this slide only refer to data; a university that wants to get into this can easily need ten times what's on the slide. This means that the overwhelming majority of researchers have never trained a model that requires more than 4 GPUs in their life, whereas you need over 100, or 500-1000, to make a good model. Moreover, “each additional GPU cuts the cost of training significantly,” SB said. “Using NVIDIA H100s cuts cost by 50%” — but there's a waiting list.
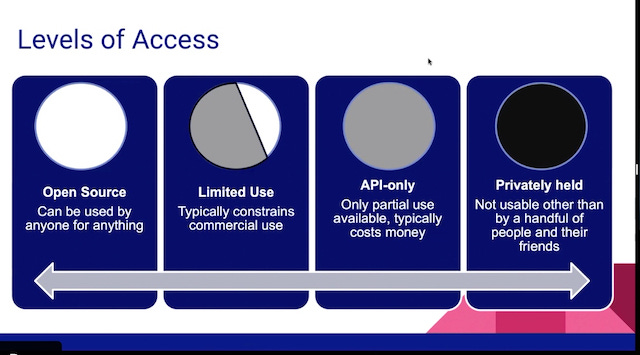
The publishing model outside the open source community is also restrictive and incompatible with current practice in mathematics. “Only 50 people will ever get access to the next two (very cool) papers,” Biderman claimed at one point “and therefore they will never be used for research.”3
SB mentioned that some Workshop organizers worried that open source models are not user-friendly; so they wouldn’t be helpful even if they were available. Fortunately, SB claimed, this is not not true, to illustrate the claim she demonstrated Pythia, an open source LLM system “that you can use in a similar way to any kind of deep learning system.”
In conclusion, SB expressed an interest in knowing what people want from AI and what's preventing them from using it.
SB’s answers to questions were also enlightening. Asked why some open source projects succeed better than others, SB replied that “building a community is essential.” EleutherAI (SB’s is employed both at Booz and at EleutherAI) has a public Discord server with hundreds of daily active users. “Managing volunteers is definitely an interesting challenge” but “people keep coming back and keep contributing.”
To a questioner who wondered how an open source community can be encouraged to collaborate and prevented from being coopted by other interests, SB claimed there was already a huge amount of collaboration; “we all know each other, we all like each other.” Regarding “other interests,” SB mentioned “a communication breakdown” between open source research efforts and for-profit companies that don’t encourage open source.
Among all speakers at the panel, only SB acknowledged legal problems with training on data downloaded from the internet. People in the large-scale AI community are under the impression that doing this is fair use, or at least that "it's not something you're going to get in trouble with, because everybody does it." This places them in a “legally awkward situation” and for “those who don't have an army of lawyers there's a huge barrier to doing work that involves being transparent about your data sourcing for this reason.” People
are very afraid of a lawsuit ruining them. … for the models where companies disclose where their data comes from … when large companies train models, they tend to be a mix of sources that are very carefully hammered out by company's lawyers… The uncertainty of it all is a huge bottleneck. There is no publicly available dataset that is known to be fully license-compliant for training a large language model.
For this reason, SB thinks the first thing the US government could do to encourage research is “put together and release a data set.” Also: for most organizations access to computing is a major limitation. Government subsidies for more GPUs would help but there’s also a need for expertise in training a model on multiple nodes, which is fundamentally a different endeavor than on one or a small number of GPUs.
Scorecard for Biderman’s presentation:
Context 1/10, for the question that alluded to cooptation “by other interests.”
Access 10/10 because this was one of the presentation’s main themes.
Externalities 5/10, for the very candid acknowledgment of the legal risks in copying data for training sets. On the other hand, nothing was said about costs to the climate or the use of water.
Democracy 5/10, for asking “who is invited to opine on laws,” and for generally speaking for the Multitude.
Cluefulness 7/10 for consistent awareness of what we call “the real world.”
Day 2, Building an Interdisciplinary Community
This panel, moderated by Heather Macbeth, inadvertently highlighted the difficulty in realizing the ideal represented by its title. Jeremy Avigad, philosopher, computer scientist, and mathematician, and therefore arguably an interdisciplinary community even when all alone, represented the perspective of academia; while Alhussein Fawzi identifies as a member of the ML community but, based at Google/DeepMind, represents the corporate agenda. Thus Avigad scored points for this panel by acknowledging, in a slide labelled “Institutional Challenges,” that “Industrial research has to answer to corporate interests.”4 Fawzi illustrated rather than acknowledged this constraint by referring exclusively in his talk to breakthroughs by Google/DeepMind! (AlphaFold, Go, etc.)
Though Avigad began by saying that mathematics needs both symbolic and neural methods, his talk focused almost exclusively on the former, specifically formal methods.

His impressive list of ways formalization can be useful for mathematics (copied above) includes two items particularly relevant to this newsletter: “providing access” for people for whom traditional means are less available; and as a model for “cooperation and collaboration,” clearly one of the primary virtues Avigad sees in the process of formalization, which he compared to “an old-fashioned barn-raising,” as illustrated by a clip from the film Witness. Avigad was one of many speakers who insisted that incentive and reward structures need to be changed to assess and acknowledge the value of collaborative work.
Although Avigad offers a lucid summary of the differences between mathematics and computer science,5 his conclusion is that the two disciplines “need each other.” In response to a question, he goes so far as to say “I think every mathematician should use Github to collaborate with others.” This was one of numerous occasions on which Workshop participants suggested that it is incumbent upon mathematics to incorporate the alien practices of the neighboring field. At least Avigad was evenhanded; arguing that progress requires working together of symbolic (formal) and neural (ML) methods, he stated that “computer scientists won't get anywhere without that," which I read as an implicit challenge to those — at Google in particular — who expect that self-trained systems will learn to “play” mathematics better than humans, in the same way that AlphaZero learned to “play” Go.
The main point I retained from Fawzi’s talk was that there is a tradeoff between interpretability and performance of computer systems. Is this a surrogate for the contrast between academic and corporate interests? Fawzi did acknowledge the importance of understanding for mathematicians.
Several of the questions that Macbeth, as moderator, forwarded to the panelists had to do with benchmarks. Fawzi thought quantifying interpretability might be a plausible quantitative benchmark for progress; in the same vein, he also thought mathematicians’ insights might help make AI more interpretable. Avigad made the important point that mathematical research is often not benchmark-driven. “In mathematical inquiry you often don't even know what the questions are” — another important difference between the two fields.
Scorecard for “Building an Interdisciplinary Community”:
Context 5/10, for Avigad’s recognition of the corporate need to respond to corporate interests, and for Fawzi’s comments on interpretability vs. performance.
Access 3/10 for Avigad’s brief mention of the question of access.
Externalities 0/10, for Fawzi’s missed opportunity to talk about copyright issues when he pointed out that ML needs lots of data.
Democracy 3/10, for Avigad’s mention of incentives and rewards.
Cluefulness 0/10. The speakers could certainly have responded to the broader discussion around AI but the organizers made no effort to include this here.
Day 2, Challenges and Barriers Panel
The second day ended with a lively panel in which Avigad and Biderman were joined by computer scientists Ursula Martin and Carlo Angiuli; Tao was again the moderator; and the topic, as the title indicates, was Challenges and Barriers. Some highlights:
Avigad: A big challenge is creating a space for younger people to succeed. How will working in this area count in hiring decisions?
Martin: There's nothing like a lot of external money to make a dean kind of wake up and start looking at the world differently.… There has to be a political dimension,… some kind of top-down leadership.
Martin: How does this kind of work fit in the mathematical pipeline? There are pieces of math that can be verified and embedded in a broader paper; this is how it's done in industrial bug-checking software.
Biderman: We don't know what you'all want; we'd be thrilled to help with specific problems.
Angiuli: Does using AI in some way count as math? Is it published in math or CS journals?
Tao expressed the hope that “the definition of what mathematics is becomes broader.”
The fact that the resources needed for AI research at this level are mainly found in private corporations was a matter of general concern. Biderman stressed that this applies to training opportunities as well as funds, and sees a “huge drain from academia to AI corporations.”
Avigad again argued that universities are irreplaceable: “an academic environment [is] the best place to explore ideas wherever they lead without worrying about what's the bottom line. So the outflow of resources and talent to corporations is dangerous for mathematics.”
Martin: I'd like to bottle Stella's talk and send it to people in the UK who are lobbying to have a sovereign AI capability.
When Angiuli pointed out that in some places where CS and Math intersect, even the CS departments don't have enough money, Biderman argued that “the political will to spend the money” was missing.
Tao asked how PhD students in pure math can acquire the coding background needed to engage with AI. Avigad thought current math majors are comfortable with computing, Martin added that “they feel they would be lacking part of their university experience if they hadn't learned to code in some way,” and Tao revealed that he “definitely recommend[s] it to my own students.” When Angiuli pointed out that PhD students in math would have enough time to learn to use the AI systems at a high level, Avigad agreed that “what we really need are tight collaborations between computer scientists and mathematicians.” Biderman’s best advice is “to audit CS 101 for non-majors and learn to code and play Pong.”
(I wonder upon hearing this discussion: is mathematics evolving to look more like computing? And if so, is the evolution being driven by concerns about employability or by broader cultural considerations?)
At this point Tao read a question from the chat:
One of the scariest things about collaborating with AI folks is that the community is so large and powerful that you end up having to do everything on their terms.
Was this true? Martin thought “it depends on who you know” and suggested that “working with the wrong collaborators can be a learning experience”. Biderman was more optimistic, claiming that “a lot of cutting edge LLM research… nowadays is on Discord” and that “there’s a lot of community out there, places to find collaborators not at corporate giants or Turing Award winners or whatever.” Avigad opined that the second biggest institutional challenge is crossing disciplinary boundaries — in computer science or math your expected to do certain things, and specialists in the two fields don’t know how to talk to each other. Martin said the time needed to learn to collaborate could be seen as a risk. At this point I wondered: why bother?
Biderman remained optimistic, saying that several of his AI associates said, after watching the first day’s talks, that they hadn’t known “what mathematicians do that make them different from computer scientists.” And I wonder: do they know now? Even though people like Avigad were there to make important points, like the irrelevance of benchmarks in mathematics, the mathematicians at The Workshop are a self-selected group who believe that it is either desirable, or inevitable, or both, that mathematics evolve toward something that looks more, rather than less, like computer science, whether of the “scary” corporate variety or the sympathetic open source variety variant. How can this give Biderman’s colleagues an accurate impression of “what mathematicians do”?
Committee Chair Petros Koumoutsakos must have been thinking along the same lines, because at this point he intervened with a question: “it’s the century of computer science, why should they bother with math?” Biderman suggested it was because “it’s fun?” I suspect this is not Booz’s motivation; Biderman talked about AI operating on data from “the real world,” Avigad about how ideas (from mathematics) enable us to “do things,” and Angiuli reminded us that verifying software — which depends on mathematical ideas — helps guarantee that “planes don’t crash.”
The discussion took a darker turn still when Tao read a question about ethical considerations, asking whether it wasn’t dangerous to have AI “better at mathematical reasoning than humans.” Biderman revealed that “a lot of AI people” hadn’t realized6 that much work on computer vision was being used by oppressive regimes to keep track of their citizens, and concluded that “working on theorem provers is less dangerous.” I was cheered when Martin recalled the protest against the NSA — in which I participated — at January’s Joint Mathematics Meeting in Boston, and when Angiuli mentioned that a lot of funding for software and hardware verification comes from the DOD, including for unmanned drones.
The session closed with a final question by Koumoutsakos: was there a landmark problem in math that could be used to plant a flag on some mountain, like AlphaFold, or Go? Avigad’s “short answer” was the most convincing: “we don’t know, you just have to try.”
Scorecard for “Barriers and Challenges Panel”:
Context 7/10 for the discussion of scary collaborations, surveillance, unmanned drones, as well as waking up Deans with external money and the brain drain to corporations.
Access 10/10
Externalities 0/10, for saying nothing about the challenge of reducing consumption of energy and water in applying this technology
Democracy 6/10 for Martin’s comments on “top-down leadership” and for Biderman’s allusions to decentralized networks.
Cluefulness 2/10 (barely) for the question about AI danger that (sort of) echoes the conversation in the wider society.
Academics are so polite! Some of my colleagues at Columbia go so far as to use vulgar and not at all professorial language when talking about decisions by certain members of the university administration; but they become so collegial at the monthly meetings of the Arts and Sciences Faculty that no one in attendance would suspect that these decisions are at all controversial.
Michael Hardt, Antonio Negri, Multitude, New York: The Penguin Press (2004), 339-40.
In a comment on this post Geordie Williamson explained how this is possible, even though the articles are available on the arXiv.
The same slide pointed to the challenge that the academic side “encourages specialization,” and moreover that mathematicians are evaluated on the basis of expert judgments and “publication in top journals,” whereas computer scientists are judged by citation counts.
Also the differences between mathematical and empirical knowledge.
This sad commentary on the state of ethical preparation by AI researchers is one more argument in support of the “10 pillars for responsible development” recommended in the recent Manifesto posted on the arXiv by Maurice Chiodo and Dennis Müller.
Scary to hear that many CS people don't understand the difference between CS and math! No wonder they are winning.
Hi Michael, This may be a naive comment, but would the math world be impressed if an AI system could produce an accurate algorithm that would generate the sequence of all prime numbers. This wouldn't be a brute force method that simply determined if a number was divisible (or prime), but an actual algorithm for predicting the sequence of primes or as Marcus du Sautoy called it "The Music of the Primes". Alternatively, could an AI theorem prover answer the question of whether there are an infinite number of twin primes. Simple questions, tough to answer for humans...